After reading Designing Data-Intensive Applications you certainly feel the need of going down to the sources to learn about the state of the art of the current limits of distributed systems.
One of the hardest problems within distributed systems is distributed transactions, and that’s why most of the NoSQL databases dropped many transactional guarantees, prioritizing scalability.
Calvin: Fast Distributed Transactions for Partitioned Database Systems paper is “a transaction scheduling and data replication layer” that supports distributed transaction using a deterministic order guarantee:
Calvin is designed to run alongside a non-transactional storage system, transforming it into a shared-nothing (near-)linearly scalable database system that provides high availability and full ACID transactions.
The key technical feature that allows for scalability in the face of distributed transactions is a deterministic locking mechanism that enables the elimination of distributed commit protocols.
Fundamentals
The problem: distributed transactions
The contention footprint (the total duration that a transaction holds its locks) of two-phase commit protocols is very high because locks must be held not only during the transaction execution but during the whole agreement protocol.
The solution: agreement outside transactional boundaries
When multiples nodes need to agree upon a transaction, they do it before the actual transaction and locking. Plans must be deterministic. Once they’ve agreed, the transaction must be executed to completion according to the plan:
- Node failure recovery: either from a replica that ran the plan, or replaying history of the plan.
Background: deterministic database systems
Events that prevent committing local changes fall into two categories:
- Nondeterministic: node failures.
- Deterministic: transaction logic.
There’s no essential reason for aborting transaction because of deterministic events. A transaction shouldn’t wait for, let’s say, an external event, and any other logic is deterministic.
On node failure, if a replica is performing the same operations, there’s no need to wait for the recovery of the failed one, so there’s no need for aborting because of nondeterministic events either.
For this to work, replicas need to maintain the same order of transactions to avoid divergence. This way replicas can be consistent just replicating database input.
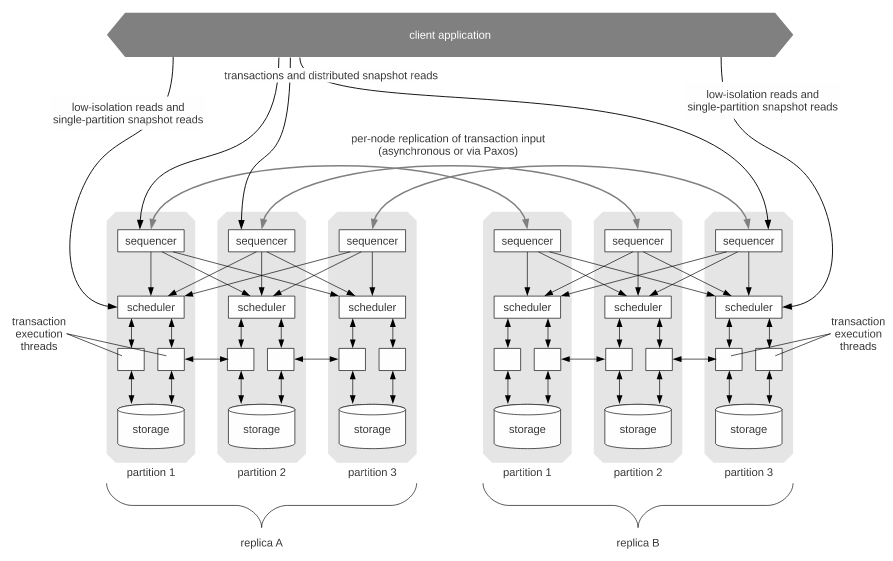
System architecture
Layers:
- Sequencer: places transactional inputs into a global sequence. Handles replication and logging.
- Scheduler: orchestrates execution in threads with a deterministic locking scheme that guarantees equivalence to the serial order.
- Storage: physical data layout. It just requires a CRUD interface.
Sequencer
Calvin divides time in 10-millisecond epochs. Sequencers collect transactions within the same epoch in batches. As the batch is replicated, a message is sent to the scheduler in every partition, containing:
- The sequencer’s unique node ID.
- The epoch number (which is synchronously incremented every 10ms).
- All transaction inputs.
Replication
Asynchronous mode: one replica (master) forwards immediately all transaction requests to sequencers at the same node, and when it compiles each batch it sends it to all other (slave) sequencers in its replication groups. This has extremely low latency at the cost of complexity in failover: on master failure, all sequencers at the same replica and its replication group must agree on the last valid batch sent and which transactions were at that batch (as sequencers only have a partial view).
Paxos-based synchronous mode: sequencers within a replication group agree on a combined batch of transaction requests.
Scheduler
Each node’s scheduler is responsible for locking records stored at that node’s storage component (even for transactions that access records stored on other nodes).
Locking protocol resembles two-phase locking with two added invariants:
- For any pair of transactions A and B that both request exclusive locks on some local record R, if transaction A appears before B in the serial order provided by the sequencing layer then A must request its lock on R before B does. Calvin implements this by serializing all lock requests in a single thread. The thread scans the serial transaction order sent by the sequencing layer; for each entry, it requests all locks that the transaction will need in its lifetime. All transactions are therefore required to declare their full read/write sets in advance.
- The lock manager must grant each lock to requesting transactions strictly in the order in which those transactions requested the lock
Clients specify transaction logic as C++ functions.
Transaction phases:
- Read/write set analysis: notes the elements of the read and write that are stored locally, and the active (writes) and passive (reads) nodes that have elements present in the transaction.
- Perform local reads.
- Serve remote reads: results are sent to all actively participant nodes.
- Collect remote read results.
- Transaction logic execution and applying writes.
If transaction logic depends on reads (dependent transactions) Calvin modifies client transaction code so the full read/write set is discovered in advance.
Disk-based storage
Following the same principle of “move as much as possible before the locks”, when a sequencer receives a request for a transaction that might be affected by disk stall, the transaction is delayed but the reads are sent so they’re brought from disk to memory (warm-up). Calvin seems to be surprisingly sensible to accuracy on disk I/O latency prediction.
Highlights
:O
- “Our Calvin implementation is therefore able to achieve nearly half a million TPC-C transactions per second on a 100 node cluster. It is notable that the present TPC-C world record holder (Oracle) runs 504,161 New Order transactions per second, despite running on much higher end hardware than the machines we used for our experiments”
Although Calvin doesn’t make initial assumptions about data storage structure, there’s some information about getting the most out of specific storage.
Another key element is replication through input and determinism, reducing coordination overhead.
The design strategy of rethinking two-phase commit by moving as much work as possible outside the transaction can be a big boost. Requiring transaction logic to be sent and analyzed in advance seems complex, but I’d like to give it a try in actual use cases. Although it requires a change in mindset over traditional session transactions, it might be a great optimization enabler.